
Your Web Analytics Data is Lying to You, so Fix it Already
Yesterday I took part in a webinar discussion with Experian’s Simon Trilsbach on the topic of data quality (DQ). It was a great session and we received some good questions after the presentation about how to go about addressing DQ within your business.
In the meantime, I wanted to extend the discussion I had with Simon yesterday by looking at a practical example of DQ that many marketers probably face without even realizing it. That is, analyzing traffic sources/acquisition data within your web analytics suite.
Your traffic sources report contains important data that offers insight into how visitors landed on your site and it's a common starting point for many analytics users. But the real value in website acquisition data isn’t the icing, it’s the cake. Tools like Google Analytics and Adobe Analytics let you go beyond looking at channel groupings by allowing you to segment, filter, sort and drill down into your data to discover things like why your visitors come to your site and what they do after they arrive.
For example, let’s say you have display banner ads driving traffic to your site from multiple ad sources (e.g. Yahoo, Facebook, MSN, etc). And within each source, you've bought multiple ad placements, each of which contains unique creative and copy. Assuming you’ve tagged your ads correctly a tool like Google Analytics will be able to tell you how much traffic the ads drove to your site, which sources drove the best quality traffic, and which individual ad placements performed best.
That’s all well and good, but the problem with website acquisition data is that it’s not terribly accurate out-of-the-box, and just how accurate it is can depend on a lot of things (e.g., the quality of your analytics implementation, if you’ve tagged inbound links correctly, etc).
Let’s take a look at a real-world example.
Here’s some data I’ve pulled from one of the many web properties I have access to in Google Analytics (It is important to note that this problem can and does affect all major web analytics tools, not just GA.
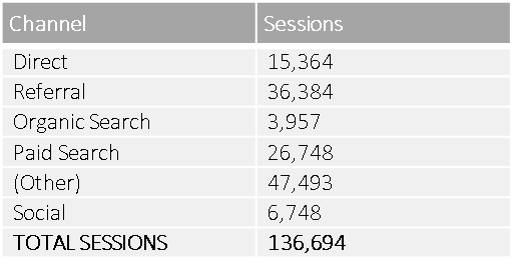
If you’re not familiar with what these channel groupings are, check out this handy resource for some definitions.
So, based on the above acquisition data it looks like most of this website’s traffic came through (Other), which is a placeholder GA uses for either other advertising mediums (as in other than paid search or display), or sometimes its traffic GA simply can’t identify. The second biggest channel driving traffic to this site is referrals (i.e. external domains), followed by paid search (i.e. AdWords). Seems simple enough, right? Unfortunately, this data is way off.
Here’s what the data looks like after it has been cleaned.
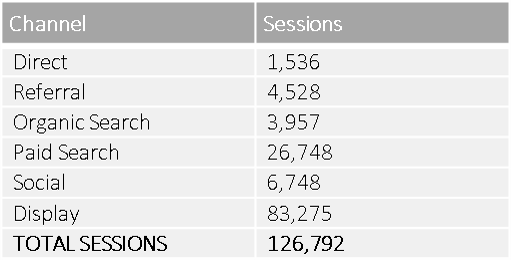
Hmmm, looks a little different. Let’s compare these visually.
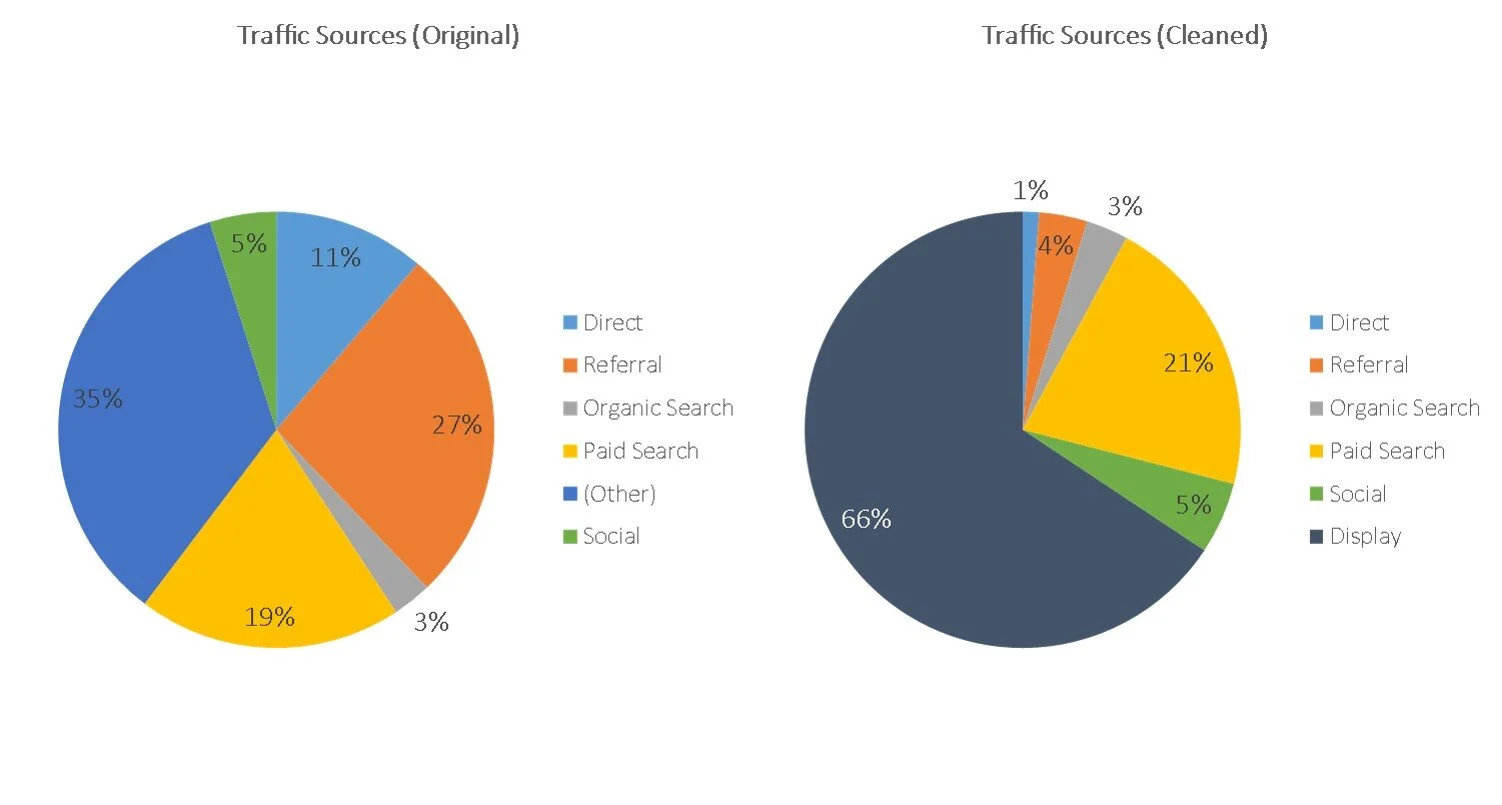
Yikes.
As you can see there’s a big difference between the raw and cleaned data. For one, we’ve dropped the (Other) category and added Display. But more importantly, in the raw data you can see that the primary traffic driver was Other (35%) followed by Referrals (27%), whereas in the cleaned data it’s Display (66%) followed by Paid Search (21%). So why was the raw acquisition data so far off the mark?
There were a number of reasons why this happened. First of all, this client had set up an onsite redirect which resulted in GA counting internal traffic as referrals. There are lots of ways to fix this, which range from your technical approach to handling the redirect (e.g. server-side vs JavaScript), to your GA implementation (creating a filtered view) to simply applying a few filters on the fly when running reports.
It’s worth noting that there could be reasons why you would want to track internal redirects, but this wasn’t the case with this client. In fact, this issue not only resulted in the acquisition data being distributed incorrectly across channel groupings, it also inflated the total number of visits/sessions to the site. The internal referrals accounted for 9,902 sessions that were not true inbound visits, which meant the real site sessions value was 126,792, not 136,694.
But the problems didn’t end there. Both the referrals and direct channel groupings counted sessions that didn’t belong to those sources, which was the result of untagged ads. Tagging any inbound link, not just ads, is key to unlocking deeper, more actionable insight, and it’s one of the most common activities that is overlooked. Unfortunately, not tagging your ads doesn’t just mean you can’t analyze and segment paid traffic, it can also mess up your acquisition data by attributing sessions to the wrong channel group. In the case above, a large share of traffic that was tagged as direct, referral and (Other) should have been attributed as display.
Whether you working with Google Analytics, Adobe Analytics, or some other analytics software, there are plenty of reasons why misattribution happens in out-of-the-box traffic sources/acquisition reports. I won't go into why this happens or how to fix it here. But if you’re interested in learning more about the topic this article is a great place to start.
The point I want to get across is that data quality is an issue that affects everyone, regardless of your role, business function or the analytics tool or vendor you’re tied to. And it's not limited to those dealing with big, complex and distributed datasets either. Even something as simple as a traffic sources report can lead you astray. Indeed, I often see channel acquisition data in Google Analytics being taken at face value when I know it’s flat-out wrong. In the words of Himanshu Sharma (a great mind in the analytics world), many analytics reports are not “what you see is what you get.”
There are many ways you can go about addressing DQ issues. If you're dealing with platform-based analytics (e.g. your website, an app, etc), you can focus on optimizing your analytics implementation. Another avenue to address data quality issues is through investment in DQ software and vendors. And finally, you can also overcome this challenge through people. A good analyst familiar with your data will know how to spot potential anomalies or issues with your data. They’ll know where to look, and they’ll usually know how to fix (or clean) your data so it’s usable.
No matter how far along your analytics journey, data quality should be a priority from day one. Ignore it, and you run the risk of making poor and untimely business decisions based on bad data. On the other hand, by putting effective data quality processes and controls in place, you can spend more time analyzing good day while decreasing your time to insight and action.
